
See discussions on Reddit
In JavaScript, objects are handy. They allow us to easily group multiple pieces of data together. After ES6, we got a new addition to the language - Map. In a lot of aspects, it seems like a more capable Object with a somewhat clumsy interface. However, most people still reach for objects when they need a hash map and only switch to using Map when they realize the keys can't just be strings for their use cases. As a result, Map remains underused in today's JavaScript community.
In this post, I will break down all the reasons when you should consider using Map more and its performance characteristics with benchmarks.
In JavaScript, Object is a pretty broad term. Almost everything can be an object, except for two bottom types -
nullandundefined. In this blog post, Object only refers to plain old objects, delimited by a left brace{and a right brace}.
TL;DR:
- Use
Objectfor records where you have a fixed and finite number of properties/fields known at author time, such as a config object. And anything that is for one-time use in general. - Use
Mapfor dictionaries or hash maps where you have a variable number of entries, with frequent updates, whose keys might not be known at author time, such as an event emitter. - According to my benchmarks, unless the keys are strings of small integers,
Mapis indeed more performant thanObjecton insertion, deletion and iteration speed, and it consumes less memory than an object of the same size.
Why Object falls short of a hash map use case
Probably the most obvious downside of using objects for hash maps is that objects only allow keys that are strings and symbols. Any other types will be implicitly cast to string via the toString method.
const foo = [];
const bar = {};
const obj = { [foo]: 'foo', [bar]: 'bar' };
console.log(obj); // {"": 'foo', [object Object]: 'bar'}
More importantly, using objects for hash maps can cause confusion and security hazards.
Unwanted inheritance
Before ES6, the only way to get a hash map is by creating an empty object.
const hashMap = {};
However, upon creation, this object is no longer empty. Although hashMap is made with an empty object literal, it automatically inherits from Object.prototype. That's why we can invoke methods like hasOwnProperty, toString, constructor on hashMap even though we never explicitly defined those methods on the object.
Because of prototypal inheritance, we now have two types of properties conflated: properties that live within the object itself, i.e. its own properties, and properties that live in the prototype chain, i.e. inherited properties. As a result, we need an additional check (e.g. hasOwnProperty) to make sure a given property is indeed user-provided, as opposed to inherited from the prototype.
On top of that, because of how the property resolution mechanism works in JavaScript, any change to Object.prototype at runtime will cause a ripple effect in all objects. This opens the door for prototype pollution attacks, which can be a serious security issue for large JavaScript applications.
Fortunately, we can work around this by using Object.create(null), which makes an object that inherits nothing from Object.prototype.
Name collisions
When an object's own properties have name collisions with ones on its prototype, it breaks expectations and thus crashes your program.
For example, we have a function foo which accepts an object:
function foo(obj) {
//...
for (const key in obj) {
if (obj.hasOwnProperty(key)) {
}
}
}
There is a reliability hazard in obj.hasOwnProperty(key): given how property resolution mechanism works in JavaScript, if obj contains a user-provided property with the same name hasOwnProperty, that shadows Object.prototype.hasOwnProperty. As a result, we don't know which method is going to get called exactly during runtime.
Some defensive programming can be done to prevent this. For example we can "borrow" the "real" hasOwnProperty from Object.prototype instead:
function foo(obj) {
//...
for (const key in obj) {
if (Object.prototype.hasOwnProperty.call(obj, key)) {
// ...
}
}
}
A shorter way might be invoking the method on an object literal as in {}.hasOwnProperty.call(key) however it is still pretty cumbersome. That's why there is a newly-added static method Object.hasOwn.
Sub-optimal ergonomics
Object doesn't provide adequate ergonomics to be used as a hash map. Many common tasks can't be intuitively performed.
size
Object doesn't come with a handy API to get the size, i.e. the number of properties. And there are nuances to what constitutes the size of an object:
- if you only care about string, enumerable keys, then you can convert the keys to an array with
Object.keys()and get itslength. - if you want to account for non-enumerable string keys, then you have to use
Object.getOwnPropertyNamesto get a list of the keys and get its length. - if you are interested in symbol keys, you can use
getOwnPropertySymbolsto reveal the symbol keys. Or you can useReflect.ownKeysto get both string keys and symbol keys all at once, regardless if it is enumerable or not.
All the above options take a runtime complexity of O(n) since we have to construct an array of keys first before we can get its length.
iterate
Looping through objects suffers from similar complexity.
We can use the good old for ... in loop. But it reveals inherited enumerable properties:
Object.prototype.foo = 'bar';
const obj = { id: 1 };
for (const key in obj) {
console.log(key); // 'id', 'foo'
}
We can't use for ... of with an object since by default it is not an iterable, unless we explicitly define the Symbol.iterator method on it.
We can use Object.keys, Object.values and Object.entries to get a list of enumerable, string keys (or/and values) and iterate through that instead, which introduces an extra step with overhead.
Finally, the insertion order is infamously not fully respected. In most browsers, integer keys are sorted in ascending order and take precedence over string keys even if the string keys were inserted before the integer keys.
const obj = {};
obj.foo = 'first';
obj[2] = 'second';
obj[1] = 'last';
console.log(obj); // {1: 'last', 2: 'second', foo: 'first'}
clear
There is no easy way to remove all properties from an object, you have to delete each property one by one with the delete operator, which has been historically known to be slow. However, my benchmarks show that its performance is actually not an order-of-magnitude slower than Map.prototype.delete. More on that later.
check property existence
Finally, we can't rely on the dot/bracket notation to check for the existence of a property because the value itself could be set as undefined. Instead we have to use Object.prototype.hasOwnProperty or Object.hasOwn.
const obj = { a: undefined };
Object.hasOwn(obj, 'a'); // true
Map for Hash Map
ES6 brings us Map. It is much more suited for a hash map use case.
First of all, unlike Object, which only allows keys that are strings and symbols, Map supports keys of any data type.
However if you are using
Mapto store meta-data for objects, then you should useWeakMapinstead to avoid memory leak.
But more importantly, Map provides a clean separation between user-defined and built-in program data, at the expense of an additional Map.prototype.get to retrieve entries.
Map also provides better ergonomics: A Map is an iterable by default. That means you can iterate a map easily with for ... of, and do things like using nested destructuring to pull out the first entry from a map.
const [[firstKey, firstValue]] = map;
In contrast to Object, Map provides dedicated APIs for various common tasks:
Map.prototype.haschecks for the existence of a given entry, less awkward compared to having toObject.prototype.hasOwnProperty/Object.hasOwnon objects.Map.prototype.getreturns the value associated to the provided key. One might feel this is clunkier than the dot notation or the bracket notation on objects. Nevertheless it provides a clean separation between user data and built-in method.Map.prototype.sizereturns the number of entries in aMapand it is a clear winner over the maneuvers you have to perform to get an object's size. Besides, it is much faster.Map.prototype.clearremoves all the entries in aMapand it is much faster than thedeleteoperator.
Performance extravaganza
There seems to be a common belief among the JavaScript community that Map is faster than Object, for the most part. There are people who claimed to see noticeable performance gains by switching from Object to Map.
My experience of grinding LeetCode seems to confirm this belief: LeetCode feeds a huge amount of data as the test cases to your solution and it times out if your solution is taking too long. Questions like this only time out if you use Object, but not Map.
However, I believe just saying "Map is faster than Object" is reductive. There must be some nuance that I wanted to find out myself. Therefore, I built a little app to run some benchmarks.
Important Disclaimer
I don't claim to fully understand how V8 works under the hood to optimize Map despite my many attempts to read blog posts and peek into the C++ source code. Perfectly robust benchmarking is hard, and most of us have never gone through any form of training in either benchmarking or interpreting the results. The more benchmarking I do the more it felt like a story about blind men and an elephant. So take everything I'm saying here about performance with a grain of salt. You'll need to test such changes with your application in a production environment to know for sure if there are actual performance gains from using Maps over Objects.
Benchmarking implementation details
The app has a table that shows the insertion, iteration, and deletion speed measured on Object and Map.
The performances of insertion and iteration are measured in operations per second. I wrote a utility function measureFor that runs the target function repeatedly until the specified minimal amount of time threshold (i.e. the duration input field on the UI) has been reached. It returns the average number of times such a function is executed per second.
function measureFor(f, duration) {
let iterations = 0;
const now = performance.now();
let elapsed = 0;
while (elapsed < duration) {
f();
elapsed = performance.now() - now;
iterations++;
}
return ((iterations / elapsed) * 1000).toFixed(4);
}
As for deletion, I am simply going to measure the time taken for using the delete operator to remove all properties from an object and compare it with the time with Map.prototype.delete for a Map of the same size. I could use Map.prototype.clear but it defeats the purpose of the benchmarks as I know for sure it is going to be vastly faster.
In these three operations, I pay more attention to insertion since it tends to be the most common operation I perform in my day-to-day work. For iteration performance, it is hard to come up with an all-encompassing benchmark as there are many different variants of iteration we can perform on a given object. Here I am only measuring the for ... in loop.
I used three types of keys here:
- strings, e.g.
yekwl7caqejth7aawelo4. - integer strings, e.g.
123. - numeric strings generated by
Math.random().toString(), e.g.0.4024025689756525.
All keys are randomly generated so we don't hit the inline-cache implemented by V8. I also explicitly convert integer and numeric keys to strings using toString before adding them to objects to avoid the overhead of implicitly casting.
Lastly, before the benchmark begins, there is also a warmup phase for at least 100ms where we repeatedly create new objects and maps that are discarded right away.
I put the code on CodeSandbox if you want to play with it.
I started with Object and Map with a size of 100 properties/entries, all the way to 5000000, and had each type of operations keep running for 10000ms to see how they performed against each other. Here are my findings...
Why do we stop when the number of entries reaches 5000000?
Because this is about as big as an object can get in JavaScript. According to @jmrk, a V8 engineer who is active on StackOverflow, "if the keys are strings, a regular object becomes unusably slow after ~8.3M elements (for which there is a technical reason: a certain bit field being 23 bits wide and taking a very slow fallback path when exceeded).".
string keys
Generally speaking, when keys are (non-numeric) strings, Map outperforms Object on all operations.
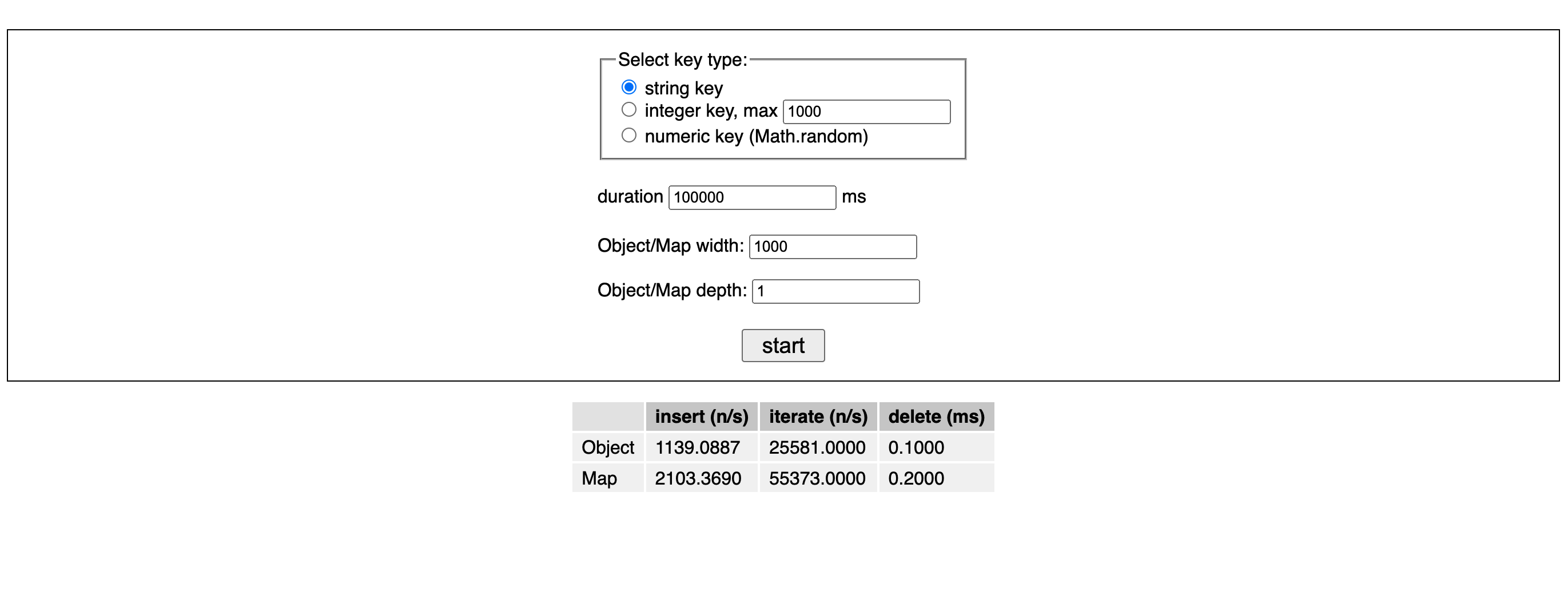
But the nuance is that when the number of entries is not really huge (under 100000), Map is twice as fast as Object on insertion speed, but as the size grows over 100000, the performance gap starts to shrink.
I made some graphs to better illustrate my findings.
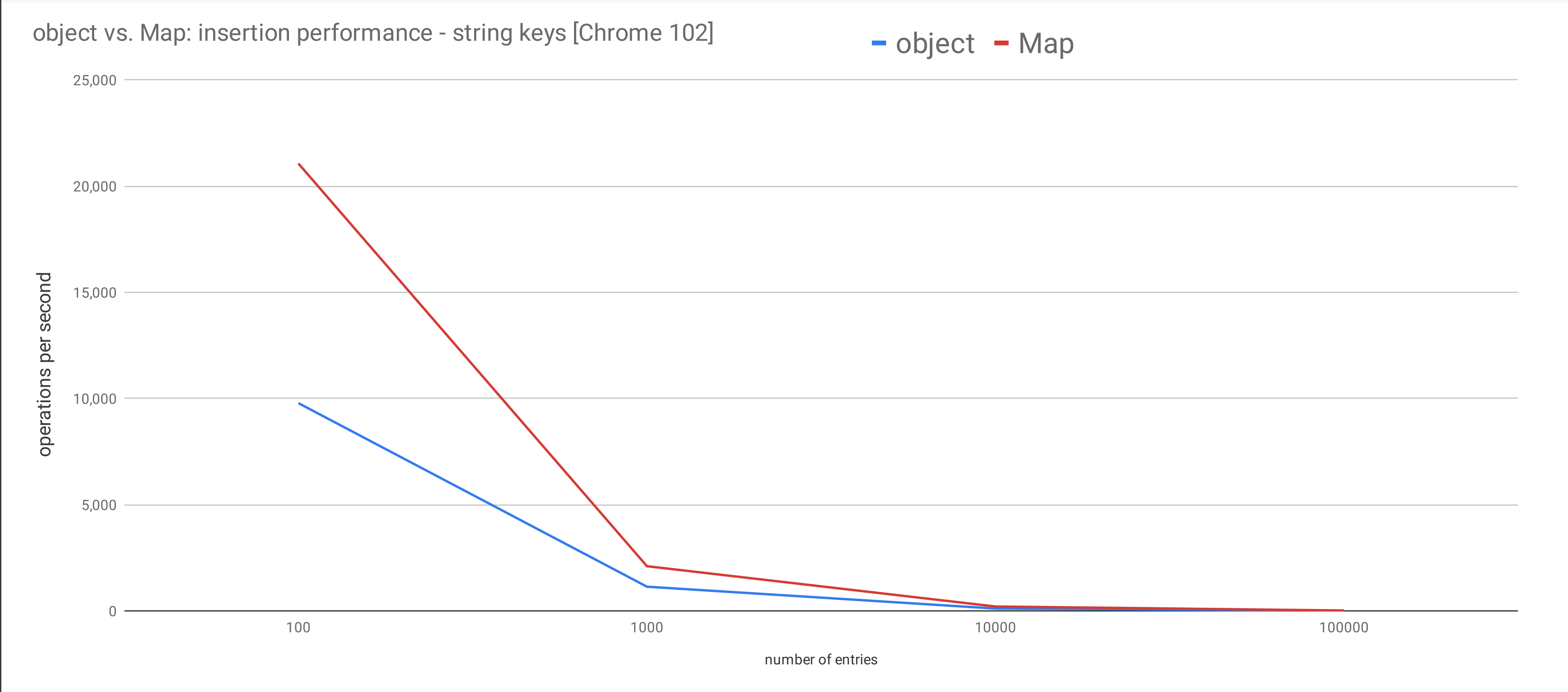
The above graph shows how insertion rate drops (y-axis) as the number of entries increased (x-axis). However because the x-axis expands too wide (from 100 to 1000000), it is hard to tell the gap between these two lines.
I then used logarithmic scale to process the data and made the graph below.
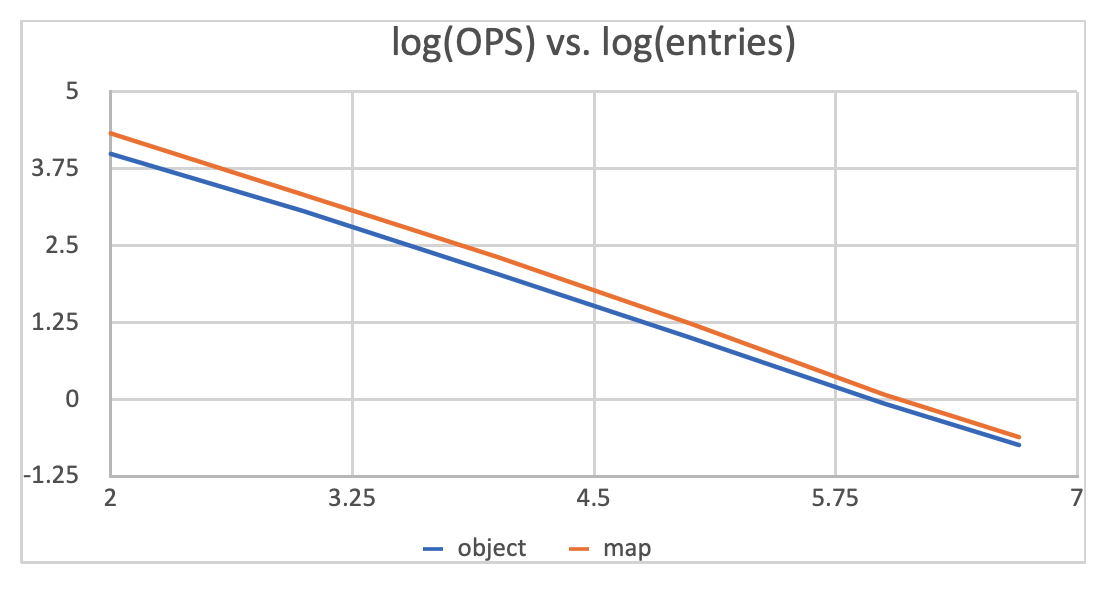
You can clearly tell the two lines are converging.
I made another graph plotting how much faster Map is in relation to Object on insertion speed. You can see Map starts out being about 2 times faster than Object. Then over time the performance gap starts to shrink. Eventually Map is only 30% faster as the size grows to 5000000.
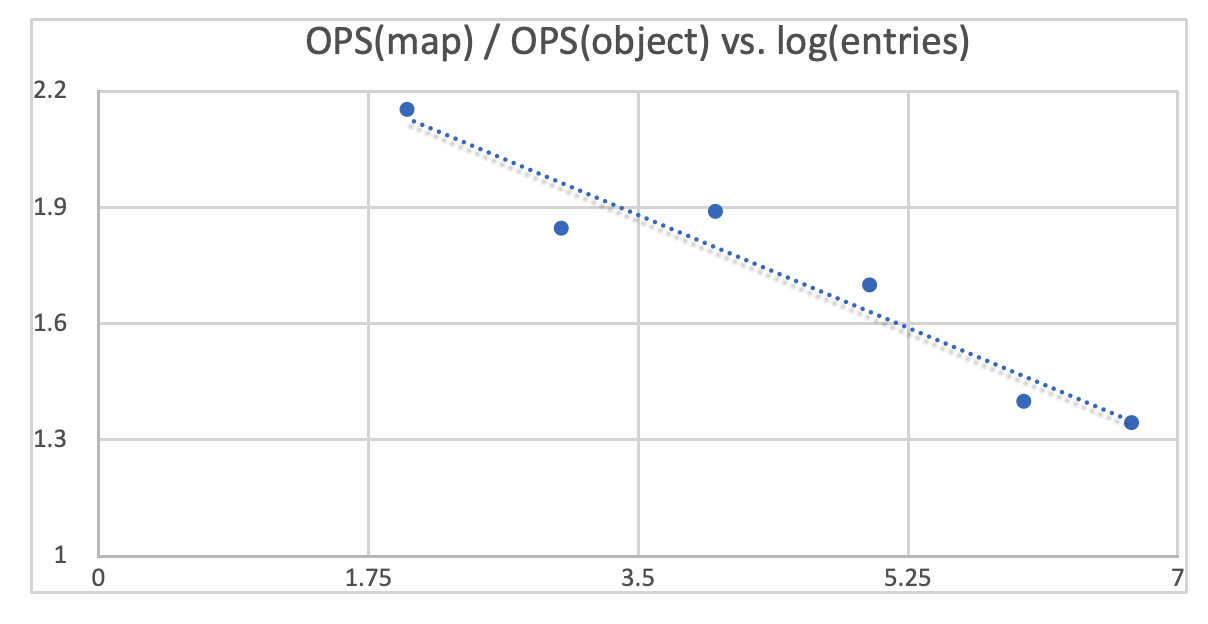
Most of us will never have more than 1 million entries in an object or map though. With a size of a few hundreds or thousands of entries, Map is at least twice as performant as Object. Therefore, should we leave it at that and head over to start refactoring our codebase by going all in on Map?
Absolutely not... or at least not with an expectation that our app becomes 2 times faster. Remember we haven't explored other types of keys. Let's take a look at integer keys.
integer keys
The reason I specifically want to run benchmarks on objects with integer keys is that V8 internally optimizes integer-indexed properties and store them in a separate array that can be accessed linearly and consecutively. I can't find any resources confirming it employs the same kind of optimization for Maps though.
Let's first try integer keys in the range of [0, 1000].
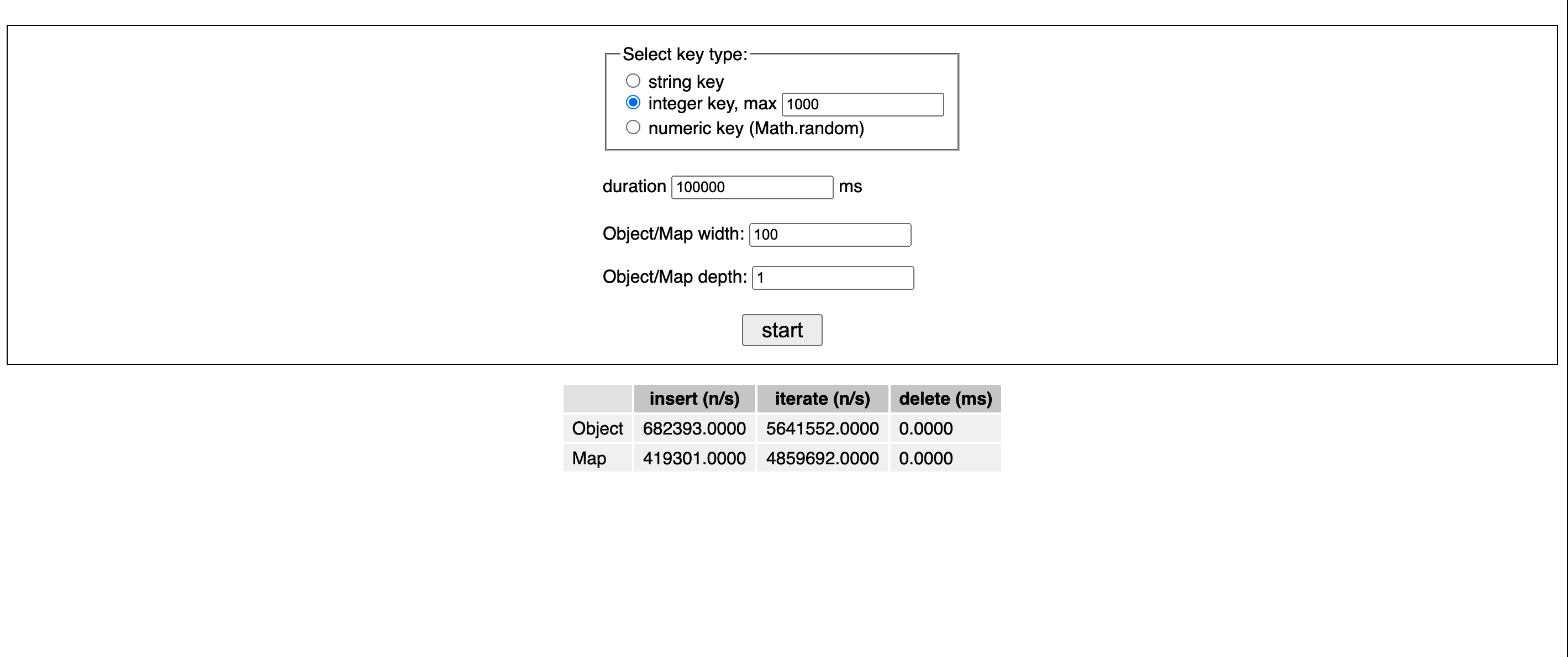
As I expected, Object outperforms Map this time. They are 65% faster than maps for insertion speed and 16% faster to iterate.
Let's widen the range so that the maximum integer in the keys is 1200.

It seems like now Map s are starting to get a little faster than objects for insertion and 5 times faster for iteration.
Note that we only increased the integer keys' range, not the actual size of Object and Map. Let's bump up the size to see how that affects the performances.

With a size of 1000 properties, Object ends up being 70% faster than Map for insertion and 2 times slower for iteration.
I played with a bunch of different combinations of Object/Map sizes and integer key ranges and failed to come up with a clear pattern. But the general trend I am seeing is that, for as the size grows, with some relatively small integer being the keys, objects can be more performant than Maps in terms of insertion, always roughly the same for deletion and 4 or 5 times slower to iterate. The threshold of max integer keys at which objects start to be slower for insertion grows with the size of the objects. For example, when the object only has 100 entries, the threshold is 1200; when it has 10000 entries, the threshold seems to be around 24000.
numeric keys
Lastly, let's take a look at the last type of keys - numeric keys.
Technically, the previously mentioned integer keys are also numeric. Here numeric keys specifically refer to the numeric strings generated by Math.random().toString().
The results are similar to those string-key cases: Maps start off as much faster than objects (2 times faster for insertion and deletion, 4-5 times faster for iteration), but the delta is getting smaller as we increase the size.
What about nested objects/maps?
You might have noticed that I have been only talking about flat objects and maps with only one depth. I did add some depth but I found the performance characteristics stay largely the same as long as the total number of entries is the same, no matter how many levels of nesting we have.
For example, with width being 100 and depth being 3, we have a total number of one million entries (100 * 100 * 100). The results are pretty much the same compared to just having 1000000 for width and 1 for depth
Memory usage
Another important facet of benchmarking is memory utilization.
Since I don't have control over the garbage collector in a browser environment, I decided to run benchmarks in Node.
I created a little script to measure their respective memory usage with manually triggered full garbage collection in each measurement. Run it with node --expose-gc and I got the following results:
{
object: {
'string-key': {
'10000': 3.390625,
'50000': 19.765625,
'100000': 16.265625,
'500000': 71.265625,
'1000000': 142.015625
},
'numeric-key': {
'10000': 1.65625,
'50000': 8.265625,
'100000': 16.765625,
'500000': 72.265625,
'1000000': 143.515625
},
'integer-key': {
'10000': 0.25,
'50000': 2.828125,
'100000': 4.90625,
'500000': 25.734375,
'1000000': 59.203125
}
},
map: {
'string-key': {
'10000': 1.703125,
'50000': 6.765625,
'100000': 14.015625,
'500000': 61.765625,
'1000000': 122.015625
},
'numeric-key': {
'10000': 0.703125,
'50000': 3.765625,
'100000': 7.265625,
'500000': 33.265625,
'1000000': 67.015625
},
'integer-key': {
'10000': 0.484375,
'50000': 1.890625,
'100000': 3.765625,
'500000': 22.515625,
'1000000': 43.515625
}
}
}
It is pretty clear that Map consumes less memory than Object by anywhere from 20% to 50%, which is no surprise since Map doesn't store property descriptors such as writable/enumerable/configurable like Object does.
Conclusion
So what do we take away from all this?
Mapis faster thanObjectunless you have small integer, array-indexed keys, and it is more memory-efficient.- Use
Mapif you need a hash map with frequent updates; useObjectif you want a fixed key-value collection (i.e. record), and watch out for pitfalls that come with prototypal inheritance.
If you know the details of exactly how V8 optimizes
Mapor simply want to call out the flaws in my benchmarks, ping me. I'll be happy to update this post based on your information!
Notes on browser compatibility
Map is an ES6 feature. By now most of us shouldn't be worried about its compatibility unless you are targeting a user base with some niche, old browser. By "old" I mean older than IE 11 because even IE 11 supports Map and at this point IE 11 is dead. We shouldn't be mindlessly transpiling and adding polyfills to target ES5 by default, because not only does it bloat your bundle size, it is also slower to run compared to modern JavaScript. Most importantly, it penalizes 99.999% of your users who use a modern browser.
Plus, we don't have to drop support for legacy browsers - serve legacy code via nomodule by serving fallback bundles so that we can avoid degrading the experience of visitors with modern browsers. Refer to Transitioning to modern JavaScript if you need more convincing.
The JavaScript language is evolving and the platform keeps getting better at optimizing modern JavaScript. We shouldn't use browser compatibility as an excuse to ignore all the improvements that have been made.
Follow me on Twitter